It’s probably very clear to regular readers that we’re big proponents of “getting granular” to drive improved pricing performance. Simply put, setting prices that align more precisely to real differences in willingness-to-pay is crucial for winning all the business you want to win, but without leaving any money on the table.
In reviewing a case study for the Journal by Peter Maniscalco, I was reminded of the importance of “getting granular” when measuring pricing performance. In Boosting ASPs (Average Selling Prices) to Drive Profitability, Peter highlights many of the pitfalls of relying on Average Selling Prices as a gauge of pricing performance and pricing process control:
ASPs can be very helpful, but also deceiving. The benefit of using the metric of an average is that it compiles a huge amount of data into a single number for drawing critical conclusions. However, this surface level ‘view’ does not provide insight at the granular level, which can reveal important factors which may be affecting ASPs.
By normalizing the extremes, Average Selling Prices can obfuscate a lot of unprofitable behaviors and outcomes. Consider, for example, how product-specific ASP comparisons between customer segments can effectively hide dramatic differences in the underlying process dynamics:

At the ASP level, these segments appear to be nearly identical. From this high-level information, it’s tempting to draw the conclusion that Segment A is performing slightly better than Segment B. We might even be tempted to figure out what we need to do differently with Segment B to have it perform more like Segment A.
But when we drill down to a more granular view, we see something very different:
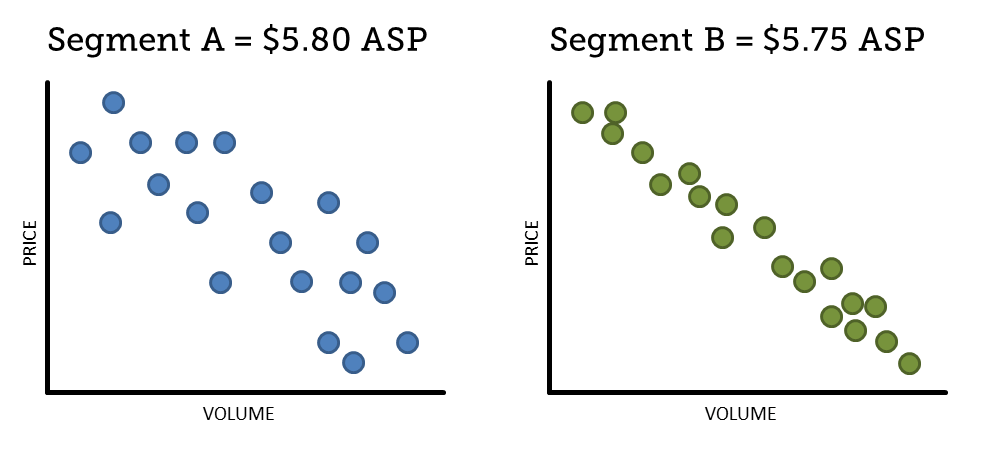
Now we can see that the outcomes in Segment B are much more consistent and rational than in Segment A. In Segment B, the relationships between price and volume are what we’d expect to see with proper price structures and diligent execution. In Segment A, however, the relatively wide dispersion indicates a lack of process control and haphazard execution.
In all likelihood, any positive ASP differences observed in Segment A are the result of pure luck, rather than intent or design. And emulating what’s happening in Segment A? That would be the last thing we’d want to do.
As Peter makes clear in the case study, averages have their place, certainly. Metrics like Average Selling Price can provide some directional information and even signal major shifts and issues. But if you really want to drive pricing improvements, you’ve got to get below surface-level metrics like Average Selling Price and drill down to a more meaningful…and more revealing…level of granularity.
Boosting ASPs (Average Selling Prices) to Drive Profitability

The use of averages are as common in business as they are in sports. Average selling prices (ASPs), however, can hide a lot of profitable truths. In this case study, Peter Maniscalco reveals how one building materials company dug deeper to find profitable opportunities.
The Fundamentals of Effective Pricing Analysis

In this on-demand training webinar, we share the fundamental concepts and principles behind effective pricing analysis, expose the critical building blocks that need to be in-place, and walk through a basic pricing analysis example to pull everything together.









